Flexibly Leverage Parallelism¶
1. Training parallelism¶
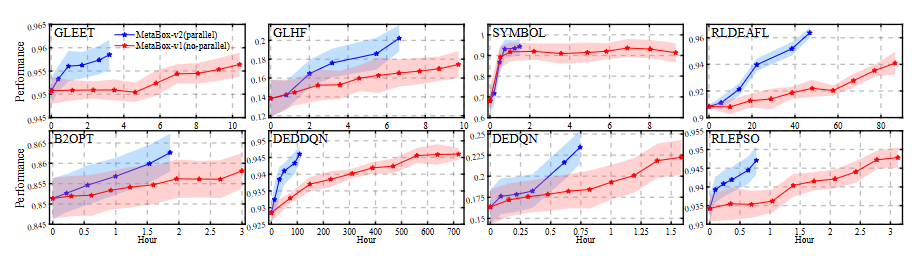
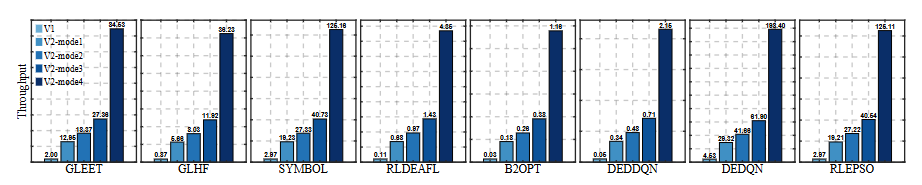
MetaBox-v2 provides VecEnv to support parallel sampling for the training of MetaBBO. The overall workflow is: trh Trainer will traverse each problem instance in the train split. For each problem instance, “batch_size” independent optimization environments are constructed and wrapped into a VecEnv, then VecEnv deploies “batch_size” subprocesses to concurrently promote the interactions between these optimization environments and the meta-level policy. Users might want to set larger “batch_size” to accelerate the learning process. However, it is better to set an approporiate “batch_size” considering the hardware used for the training. If your CPU has 64 cores, “batch_size” should be no more than 32 to ensure other processes in this hardware are not blocked. Below we show where to set the “batch_size”.
from metaevobox import Config, Trainer
# import meta-level agent of MetaBBO you want to meta-train
from metaevobox.baseline.metabbo import GLEET
# import low-level BBO optimizer of MetaBBO you want to meta-train
from metaevobox.environment.optimizer import GLEET_Optimizer
from metaevobox.environment.problem.utils import construct_problem_set
batch_size = 1 # this is sequntial training in MetaBox-v1
batch_size = 16 # this is parallel training in MetaBox-v2
# put user-specific configuration
config = {'train_problem': 'bbob-10D', # specify the problem set you want to train your MetaBBO
'train_batch_size': batch_size,
'train_parallel_mode':'subproc', # choose parallel training mode
}
config = Config(config)
# construct dataset
config, datasets = construct_problem_set(config)
# initialize your MetaBBO's meta-level agent & low-level optimizer
gleet = GLEET(config)
gleet_opt = GLEET_Optimizer(config)
trainer = Trainer(config, gleet, gleet_opt, datasets)
trainer.train()
2. Testing parallelism¶
for problem in testsuites:
for run in test_runs:
baseline.rollout_episode(problem)
The other four modes are parallel modes using Ray to accelerate the testing process. For example, “Batch” mode means we select a batch of problem instances and distribute their currrent runs to different CPU cores:
for problem_batch in testsuites:
for run in test_runs:
ray.distribute(baseline, problem_batch)
# in each CPU core
baseline.rollout_episode(problem_batch[i])
“Full” mode means we distribute all combination of problem instances and test runs to different CPU cores (as long as the CPU cores users have are enough).
ray.distribute(baseline, zip(testsiotes, test_runs))
# in each CPU core
baseline.rollout_episode(problem)
Users should select testing modes according to their hardware. Although “Full” mode introduce significant acceleration if the CPU cores are enough, it is not the case for trivial users. For other testing modes, see Config.